About Me
Nick Jones is a multi-disciplinary technologist with a background in computer science - and interests in law, government, and policy. All views expressed on this website are his own.
Projects
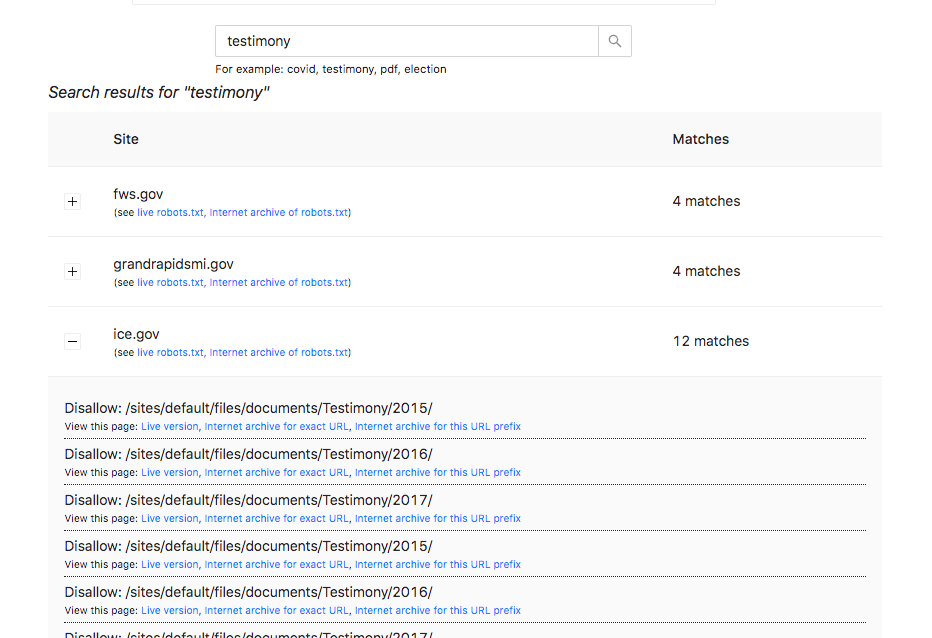
Robots.txt Database
A project that collects robots.txt files from websites across the internet, making them searchable and available for researchers to query or download in bulk. Starting with a focus on 9000+ state, local, and federal government websites. Access the raw data on Github, or search across all 9000+ robots.txt files here.
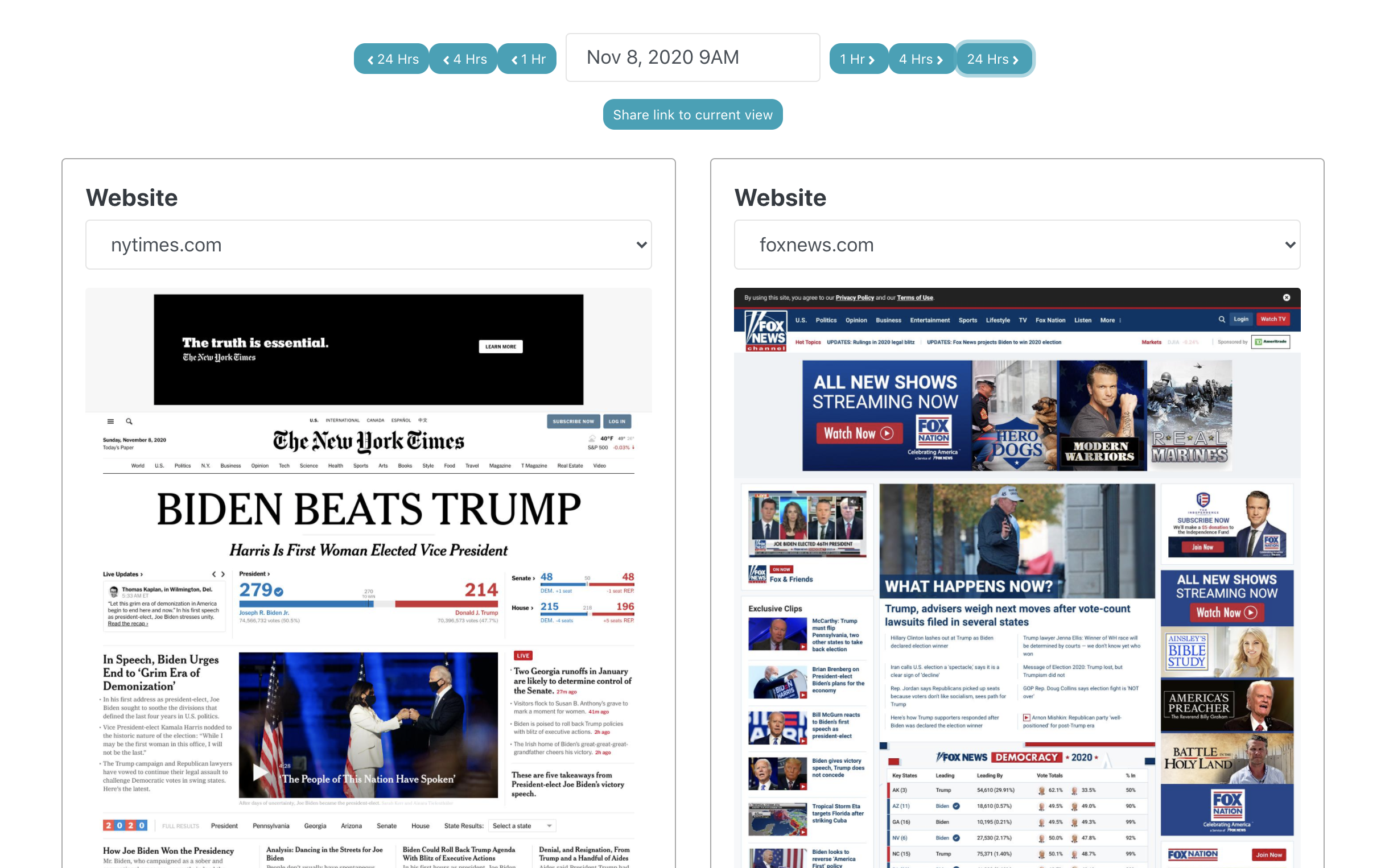
Hourly News Homepage Archive
An archive that captures what the front page of various news websites show. Screenshots are taken every hour starting January 1, 2019 and continually updated. To access the raw screenshots directly, see Github, or browse the screenshots here.
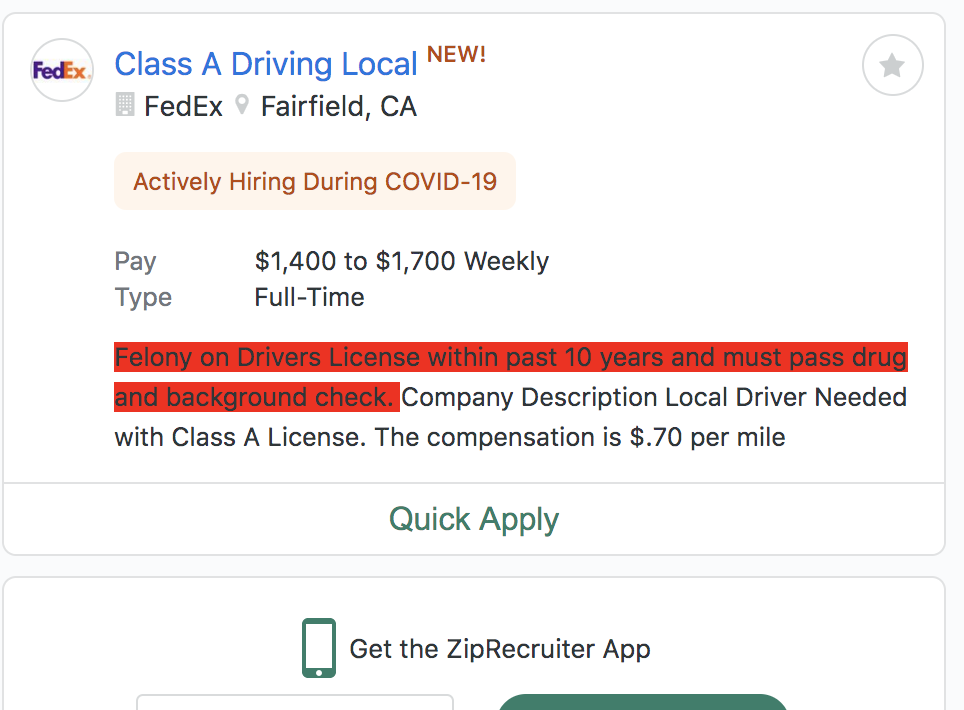
Discriminatory Postings on Online Job Boards
Online job boards are an increasingly common way for people to find jobs. How do platforms like ZipRecruiter handle potentially discriminatory job postings? I wrote code to collect job postings that have potential EEOC (Equal Employment Opportunity Commission) violations against people with criminal records, where companies include blanket exclusionary statements like "No Criminal Background" in their job descriptions. Data and writeup available on Github.
Historical SF Ballot Props Explorer
Most years, San Franciscans vote on ballot measures determining whether or not police should carry tasers, to allocate $50 million a year for homeless services, or to impose a fee on ride-hailing apps to support public transit. In some years, voters make decisions on over 30 propositions at the local, regional or state level. I built an interactive tool to help people explore 40+ years of ballot propositions and their outcomes, available here, and wrote about the process of building the interactive for Storybench.

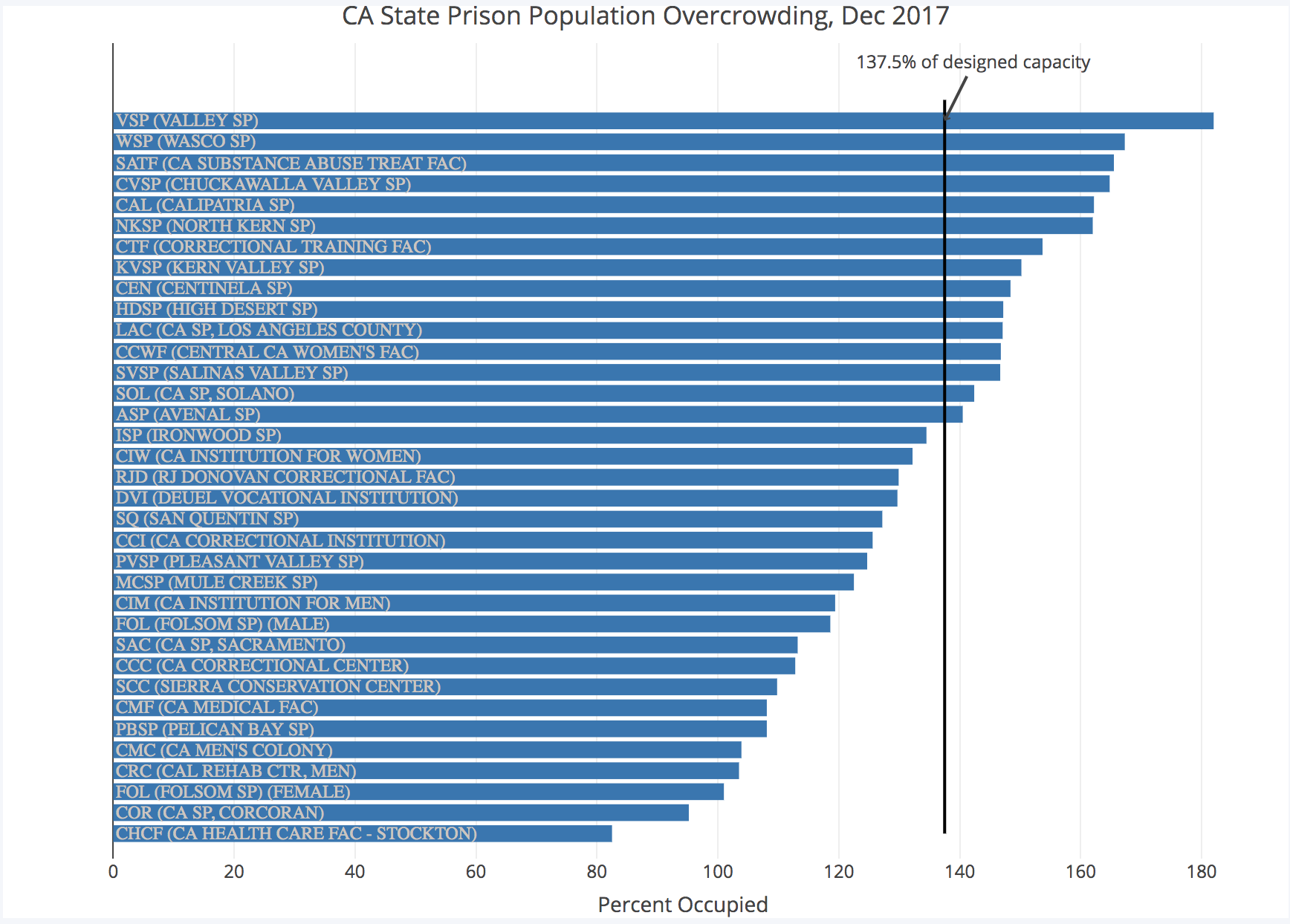
Misleading Prison Overcrowding Statistics in California
Since 2011, California has been under a court-mandated reduction of its prison population to 137.5% of its designed capacity. In order to track progress of individual prisons over time, I built a tool to parse PDFs published monthly by the CDCR and aggregate monthly population data into one easily-analyzable CSV.
The data and code are on Github; I also wrote about why the court's definition of "overcrowding" as an average across 35 prisons is extremely problematic, as many individual prisons have continued to house upwards of 160% of their designed capacities.
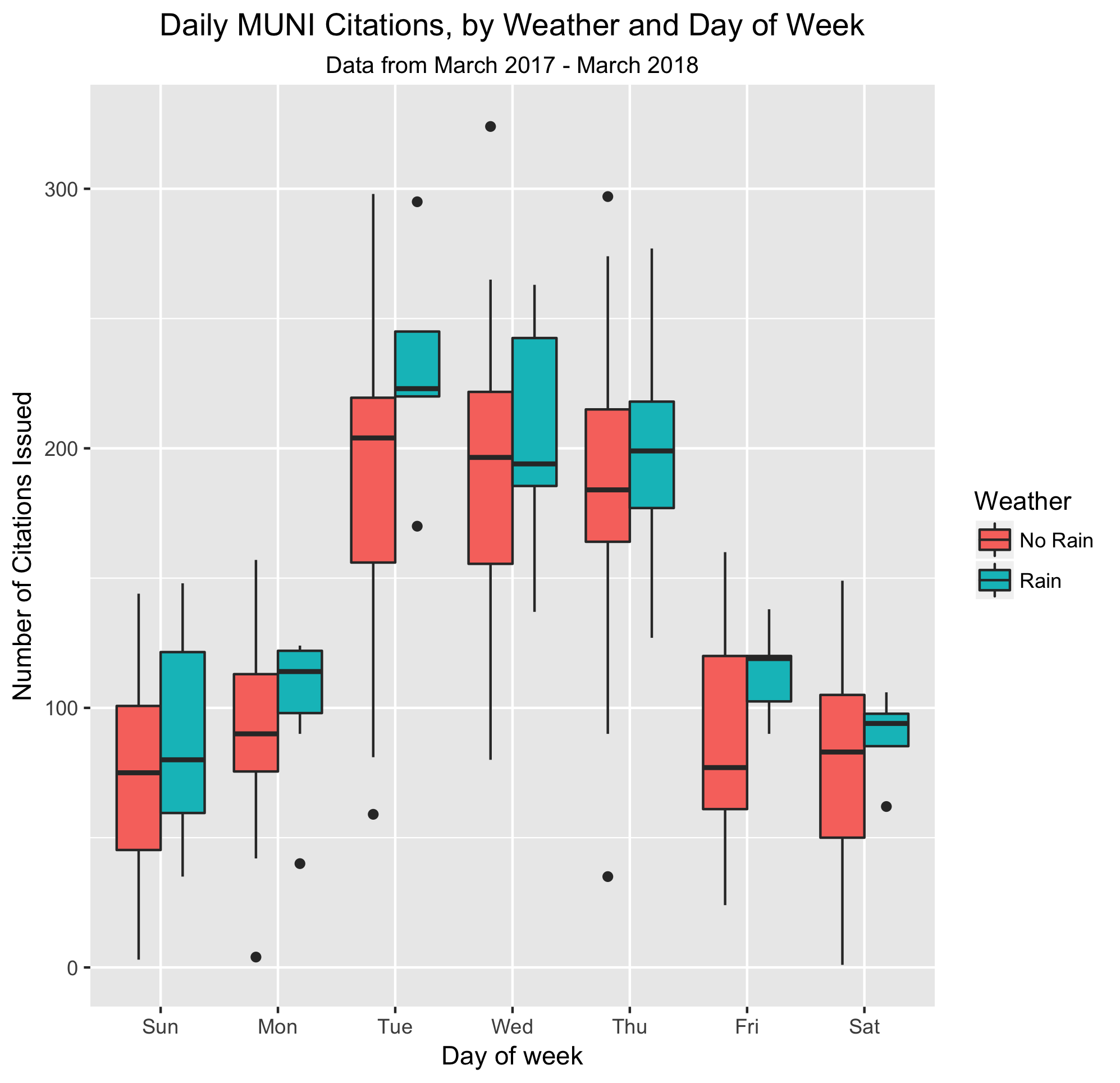
MUNI's increased ticketing on rainy days
Published on Storybench, an investigation into the relationship between bad weather and the number of citations handed out by MUNI. Using data obtained via records request from MUNI, I found an increased rate of citations on days that it rained vs. those when it didn't.
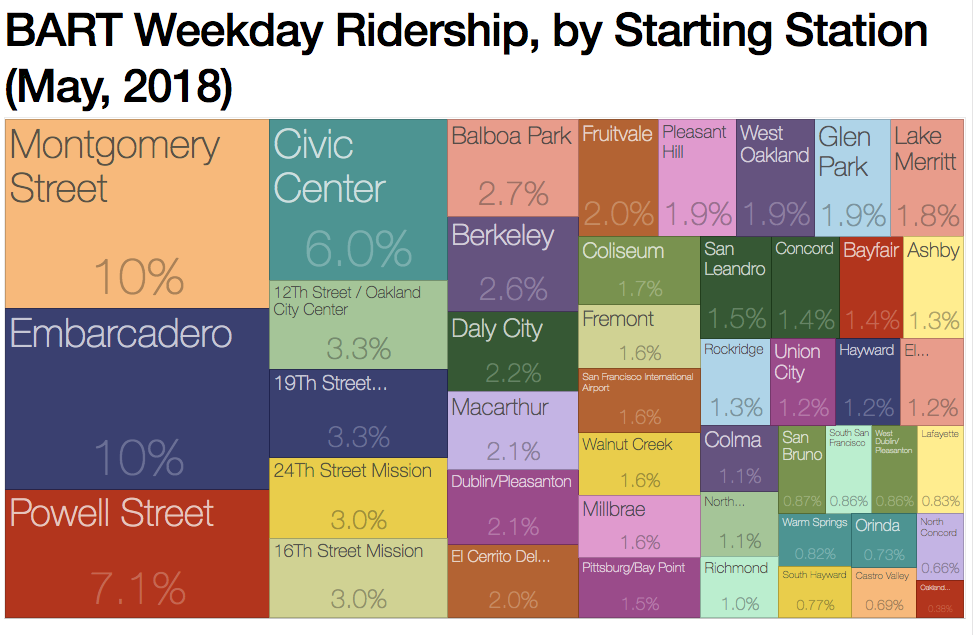
BART Ridership Visualizations
A treemap visualization of weekday BART ridership. Data came from combining .xlsx data published by BART, see Github for raw data.
Contacting me
If you'd like to follow along with new posts, provide feedback on any of my projects, or otherwise contact me, you can find me elsewhere - I would love to hear from you!